
Protecting individual privacy is paramount, given the proliferation of Personally Identifiable Information (PII) and other sensitive data collected by enterprises across all industries. One way to protect sensitive data is through PII masking e.g., consistently changing names or including only the last four digits of a credit card or Social Security Number.
What is data masking?
Data masking replaces sensitive columns in the source data with realistic test data. A data breach remediation strategy is primarily used to address areas of risk. By preserving the integrity and usability of the original, it creates an unidentifiable and secure version.
Masking is usually needed for the following types of data:
- Personally Identifiable Information (PII) such as names, email addresses, social security, and telephone numbers
- Protected Health Information (PHI) such as patient name, insurance details, diagnostic information, and medical history.
- The Payment Card Industry (PCI) is concerned with protecting consumers' financial information by the Federal Trade Commission (FTC).
Data masking is often used in non-production environments, such as software development, data science, testing, and training. Tools and processes mask sensitive data to make it unrecognizable while maintaining its functionality for authorized users.
Data Masking Process
Iterative data masking consists of five steps: data discovery, defining masking rules, assigning masking rules, deploying masking functionality, and auditing the entire process.
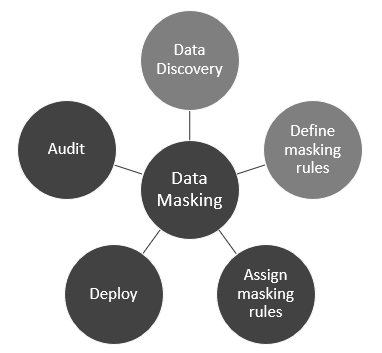
The data masking process starts with:
- Discover the data and its relationships: Your data masking tools or process should import the metadata data and be able to discover, analyze, and visualize the sensitive data within the data sources.
- Define the data masking rules: Based on the masking requirements, you should be able to define dynamic masking rules (restricting access to sensitive data with Role-Based Access Controls (RBAC)) and persistent data masking rules and, then develop different masking regulations for various types of users and data types.
- Assigning the appropriate masking rules: Your tools should be able to assign the masking rules on columns or data elements.
- Deploying the masking functions: Your tools/process should have a wide range of built-in functions, such as substitution, randomization, shuffling, and nulling out, but it should also allow you to deploy customized functionality.
- Audit reports for compliance: Your tool should be capable of generating exportable audit reports. The reports should contain the data system name, schema, table, column name, type, field, and masking rule used. This is an ongoing process.
Data masking versus encryption and tokenization
Data anonymization is the process that transforms PII data into another form to secure and protect it. The three most common data anonymization methods are data masking, encryption, and tokenization. Data masking is irreversible, while encryption and tokenization are reversible because the original values can be derived from the obscured data. Below is a brief explanation of the three methods:
Data masking
Hiding Sensitive data in nonproduction environments to protect the data from data breaches with the industry standard masking rules. Compliance and privacy regulations (PCI DSS, HIPAA, GDPR, and CPRA) mandate masking data before it is copied to a non-production environment. The algorithm used to mask the PII data must be irreversible.
Data Encryption
Encryption scrambles data using mathematical models. Without the correct decryption key, the data is unreadable. Encryption prevents interception, theft, and misuse. Common encryption algorithms include the Advanced Encryption Standard with 128-bit encoding (AES), and Elliptic Curve Cryptography (ECC).
Data Tokenization
Tokenization is when a unique identifier replaces sensitive data within a record to make it more secure. It is primarily used in Master Data Management (MDM) to facilitate matching records by generating match tokens, representing the key data points of a record for comparison while keeping the original sensitive data secure. Tokenization anonymizes data for matching purposes without exposing sensitive information.
Comparatively, tokenization allows credit card payments to be processed without revealing the card number. The data never leaves the organization and can’t be seen or decrypted by a third-party processor. Data masking is irreversible, making it more secure and less costly than tokenization. Data masking software ensures referential integrity and context across systems and databases, which is crucial for testing and data analysis. In the case of anonymized data, integrity means that the dataset maintains its validity and consistency despite being de-identified. Masked data is usable in its anonymized form, but its original value can never be recovered once it is masked.
Why data masking?
Enterprises need data masking solutions because they enable them to:
- Reduce the risk of data exposure, which is required for compliance with privacy laws, such as CPRA, GDPR, and HIPAA.
- Protect data in lower (DEV, QA, UAT, Training) environments from cyber-attacks while maintaining consistency and usability.
- Integrate with third-party apps or migrate more securely to the cloud while reducing the risk of improper data sharing.
There has never been a time when data masking tools have been as vital as they are today in protecting sensitive data and addressing the following challenges:
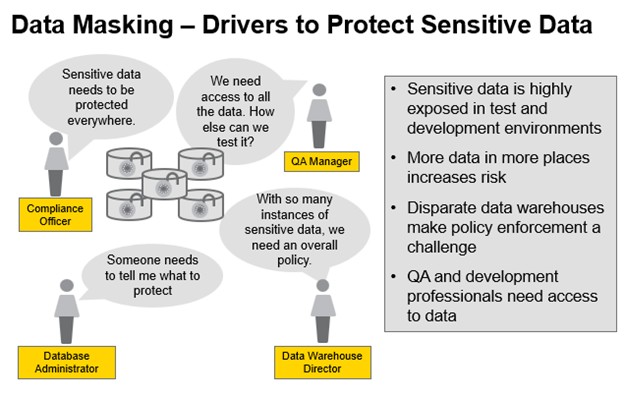
Compliance with regulatory requirements
Compliance and privacy regulations recommend data protection methodologies.
Insider threats
Employees and third parties regularly access enterprise systems to test software or analyze data. Sensitive information is often shared in development, testing, and non-production environments. Because of this, production systems are particularly vulnerable to data breaches. Ponemon Institute reports that insider threats have increased 47% since 2018, and protecting sensitive data costs companies an average of $200,000.
External threats
According to Verizon's report, personal data was compromised in 58% of data breaches in 2020. The study found that 72% of the victims were large enterprises. Given the large, varied, and fast nature of enterprise data, it is no wonder breaches proliferate. Protecting sensitive data in non-production environments can reduce the risk of leakage. This is one example of data masking.
Data governance
Role-Based Access Control (RBAC) should secure your data masking tool. The comparison of persistent or dynamic data masking shows that persistent data masking obscures a single dataset, while dynamic data masking provides granular control. Dynamic data masking allows permission to be granted or denied at various levels. Those with appropriate access rights can access the actual data, while those who are not allowed to see certain parts will be unable to see them. Masking policies can also be applied differently to different users.
Flexibility
Data masking is highly customizable. Data teams can choose which data fields get masked and how to select and format each substitute value. For example, every Social Security Number (SSN) has the format xx, where “x” is a number from 0 to 9. They can substitute the first five digits with the letter x or all nine numbers with other random numbers according to their needs.
Types of data masking
As data masking evolved, it became more sophisticated, flexible, and secure, including:
Persistent data masking
Non-production environments like those used for analytics, testing, training, and development often source data from production systems. In such cases, sensitive data is protected with static data masking; a one-way transformation that ensures the masking process cannot be undone. Repeatability is a key concept in testing and analytics because using the same input data delivers the same results. This requires the masked data values to persist over time and through multiple extractions. For software testing, static data masking is usually employed on a copy of a production database. Advanced masking tools make data look authentic, enabling software development and testing without exposing the original values.
Dynamic data masking
Dynamic data masking protects, obscures, or blocks access to sensitive data. While prevalent in production systems, it is also used when testers or data scientists require accurate data. Dynamic data masking is performed in real-time in response to a data request. Masking consistency is difficult when the data is stored in multiple systems, especially in environments that use various technologies. Dynamic data masking protects sensitive data on demand.
Dynamic data masking automatically streams data from a production environment to avoid storing the masked data in a separate database. It’s generally used for role-based security in applications, such as managing customer queries and processing sensitive health information records, and in read-only scenarios so the masked data doesn’t return to the production system after the check has been run.
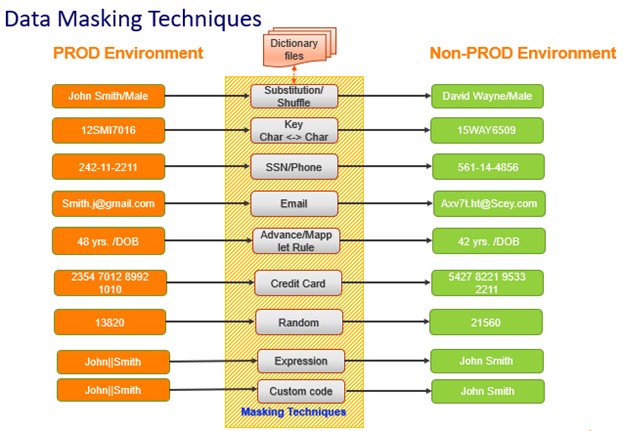
Data masking techniques
In terms of data masking techniques, there are several core techniques associated with data obfuscation, as shown in the following table:
Technique | How it works | Notes |
| Data anonymization | Remove or modify PII data | The goal is to make the data permanently anonymous and untraceable to specific people. |
| Pseudonymization | Data is swapped with random values while the original data is securely stored. | This applies to unstructured as well as structured data. |
| Substitution | Data from a dictionary is substituted for similar but unrelated data in a column of data using substitution masking. | Prevents data breaches by dummy data in the table. |
| Random | An entirely or partially generic value can be replaced with PII in a field. | Valid when PII isn’t required or when dynamic data masking is employed. |
| Shuffling | Shuffle masking swaps the data in a column with data from the same column in another row of the table. | Scrambles the actual data in a dataset across multiple records. |
| Date aging | By applying random data transformations, confidential dates can be concealed. | Requires assurance that the new random dates are consistent with the rest of the data |
| Key Masking | Key masking produces deterministic results for the same source data, masking rules, and seed value. | Data will be masked with deterministic results. |
| Nulling out | To protect PII, a null value should be applied to a data column. | A security feature that prevents unauthorized viewing. |
6 Challenges of Masking Data
Altered data must retain the essential characteristics of the originals while undergoing sufficient transformation to eliminate the risk of exposure as long as referential integrity is maintained.
Many production systems are deployed on-premises and in the cloud across various technologies in enterprise IT landscapes. To mask data effectively, here’s a checklist of must-haves:
Preserving formats
Data masking tools must understand your data and what it represents. The original format should be preserved when accurate data is replaced with fake data. For data threads involving dates, for example. A specific order is essential.
Referential integrity
Primary keys connect relational database tables. When your mask solution hides or substitutes a table's primary key, the values must be consistently changed across all databases. Thus, Sam Jones, for instance, must have a consistent identity wherever he is masked as Rick Smith.
PII discovery
Although PII is scattered across many different databases, the correct data masking tool should be able to discover where it’s hiding.
Data governance
Data access policies must be established and adhered to based on role, location, or permissions.
Scalability
Data access and extraction must be enabled in real time for structured and unstructured data.
Integration
Relational databases, NoSQL databases, legacy systems, message queues, flat files, and XML documents must all be considered data sources, technologies, and vendors.
Summary and recommendations
Data masking has become essential to enterprise efforts to comply with privacy protection regulations and address emerging generative AI data outputs.
Today, the sheer volume of structured and unstructured data, the challenging regulatory environment, and the demand for lifelike masked data require highly sophisticated data masking tools.
The wide variety of data sources (mainframe, ERP, Streaming systems and noSQL databases) makes automated PII discovery and masking even more complex, especially since every vendor touts its own data masking tools.
About the Author:

Arfi Siddik Mollashaik is a Solution Architect at Securiti.ai, USA a leading enterprise data security, privacy, and compliance firm. The firm specializes in implementing data classification, discovery, privacy, and data subject rights and protection software for organizations worldwide. Having worked with many Fortune 500 companies, he has vast experience enhancing the data protection and privacy programs of healthcare, banking, and financial companies. He can be reached at [email protected].
Editor’s Note: The opinions expressed in this guest author article are solely those of the contributor, and do not necessarily reflect those of Tripwire.
